分类
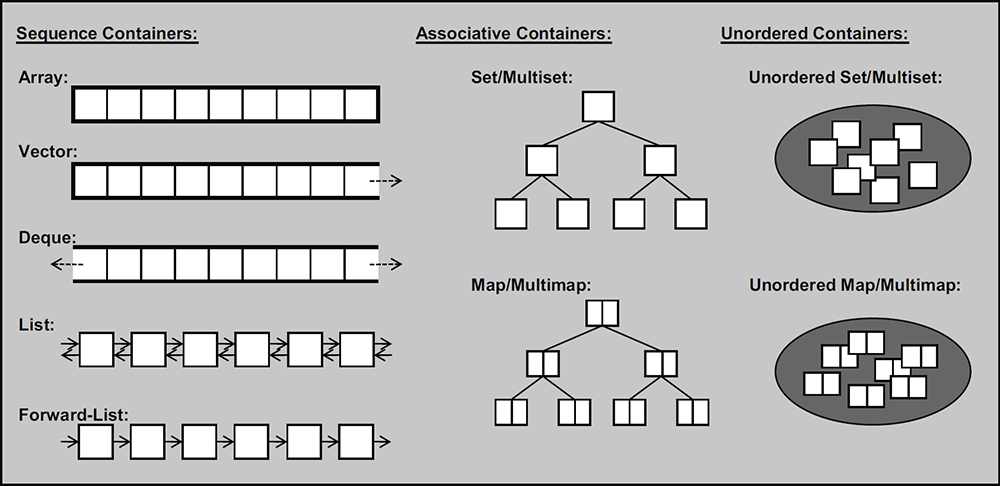
序列式容器
- 向量(
vector) 末尾可以高效增加元素的不定长顺序表,其他位置也能进行增删,但效率略慢。 - 数组(
array) 定长顺序表,C风格数组的简单包装,在算法竞赛中使用较少。 - 双端队列(
deque) 双端都可高效增加元素的顺序表,但对于中间位置元素的操作比较麻烦。 - 列表(
list) 可以沿双向遍历的链表。 - 单向列表 (
forward_list) 只能沿一个方向遍历的链表。
关联式容器
- 集合(
set) 按照特定顺序存储唯一元素的容器,可理解为自带排序和去重,底层是由节点组成的红黑树实现,节点间按照某种比较元素大小的规则(函数)进行排列。 - 多重集合 (
multiset) 按照特定顺序存储元素的容器,允许存在重复元素,和set区别就是这个不会去重。 - 映射(
map) 由 {键, 值}对 组成的集合,按照某种比较键的大小的规则(函数)进行排列,键是唯一的。 - 多重映射(
multimap),类似于map,区别在于键可以重复。
无序(关联式)容器
- 无序集合(
unordered_set) 和set区别在于不会进行排序,只关心元素是否存在,底层用哈希实现,增删改查的效率大幅高于set。 - 无序多重集合 (
unordered_multiset) 和multiset的区别同上。 - 无序映射(
unordered_map) 和map的区别同上。 - 无序多重映射(
unordered_multimap) 和multimap的区别同上。
容器适配器
容器适配器其实并不是容器,它们不具备容器的某些特点,比如:有迭代器、有 clear() 函数等等...
严格来说,适配器是把容器进行包装,使得其能实现的操作有所改变。
- 栈(
stack) 后进先出(LIFO)的容器,默认是对deque的包装。 - 队列(
queue) 先进先出(FIFO)的容器,默认是对deque的包装。 - 优先队列(
priority_queue) 可以提供常数时间的最大/小元素查找,默认是对vector的包装。
共同点
声明都是以 容器类型<参数类型,...> 名字 的形式来定义,不过参数类型的个数、形式会根据具体容器有变化。
容器共有的函数:
=: 都有赋值运算符,以及类似写法的构造方式。
begin():返回指向开头元素的迭代器。
end():返回指向末尾的下一个元素的迭代器。注意,它指向的不是具体的元素,而是末尾元素的下一个节点。
size():返回容器内的元素个数。
max_size():返回容器 理论上 能存储的最大元素个数。
empty():返回容器是否为空。
swap():交换两个容器
clear():清空容器。
使用比较运算符可以按字典序比较两个容器的大小,需要注意的是无序容器只支持 == 和 != 。
vector
vector 是一种存储数据的容器,和平时使用的数组很像,也是可以存储一组相同类型的数据,下标都是从
在进行添加和删除时,一般是在容器末尾进行操作。

- vector 可以动态分配内存,这样面对一些不好设置初始长度的场景时,我们可以少考虑一些事情。
- vector 重写了比较运算符和赋值运算符,这样我们可以方便的判断两个容器是否相等或者拷贝两个数组。
- vector 初始化的写法能够提供一些遍历,例如快速构建出有100个1的容器。
定义
常见的几种方式:
vector<数据类型> 名字,例如 vector<int> q,定义了一个存储 int 类型的容器,名为 q,这样初始长度为
vector<数据类型> 名字(长度),例如 vector<int> q(105),这样定义了初始长度为
vector<数据类型> 名字(长度, 初始值),例如 vector<int> q(105, 1),这样定义了初始长度为
使用
q.push_back(数据) 把元素添加到末尾
q.pop_back() 把末尾元素删除
q.size() 或 q.length() 获取长度
q[i] 获取下标为 i 的元素
q.front()获取首位元素,也可以使用下标 q[0]
q.back() 获取末尾元素,也可以使用下标 q[q.size()-1]
q.clear() 清空容器
q.begin() 返回一个迭代器,指向容器的第一个元素
q.end() 返回一个迭代器,指向容器的最后一个元素的后一位
q.erase(q.begin()+1, q.begin()+4) 删除容器中下标
使用示例
定义
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v1; // 定义了一个存放整型数据的vector容器
vector<double> v2; // double类型vector容器
vector<int> v3{1, 2, 3}; // 初始化为1,2,3三个元素
vector<int> v4(10, 1); // 初始化10个元素,均为1
v1.push_back(10); // 往v1内添加值为10的元素
v4.pop_back(); // 弹出v4末尾元素
return 0;
}
遍历
一般来说建议用下标。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> q(105, 1);
// 下标遍历
for (int i=0; i<q.size(); i++) {
cout << q[i] << " ";
}
cout << '\n';
// 迭代器遍历
for iterator it=q.begin(); it!=q.end(); it++ {
cout << *it << " ";
}
cout << '\n';
// auto关键字,直接按顺序获取vector里的元素。
for (auto i:q) {
cout << i << " ";
}
return 0;
}
拓展
一些常用函数
sort(q.begin(), q.end()) 对容器进行排序,默认从小到大,如果需要设置排序规则则额外定义一个 cmp 函数。
reverse(q.begin(), q.end()) 反转整个容器。
copy(q.begin(), q.end(), p.begin()+1) 把容器 q 的所有元素复制到容器 p 中,从 p[1] 的位置开始存储。
find(q.begin(), q.end(), 19) 在容器中查找 19 第一次出现的位置。
unique() 可以把相邻的重复元素去重,其本质其实是把重复元素移动到数组的末尾,如果想要实现完全去重的功能,则需要先排序后再使用该函数,例如:
vector<int> q;
sort(q.begin(), q.end()); // 先排序,否则
q.erase(unique(q.begin(), q.end()), q.end()); // 去重后删除后面那一段
易错点
vector<int> a;
for (int i=1; i<=10; i++) {
cin >> a[i];
}
注意,容器这种定义方式是没有初始长度的!这样写相当于越界访问!
可以这样写:
vector<int> a;
for (int i=1; i<=10; i++) {
int x;
cin >> x;
a.push_back(x);
}
deque
deque 是 STL 提供的 双端队列 数据结构,能够提供线性复杂度的插入和删除,以及常数复杂度的随机访问。
定义
常见的几种方式:
deque<int> q; 定义一个 int 类型的空双端队列
deque<int> q(10); 初始长度为 10,线性复杂度。
deque<int> q(10, 1); 初始化为 10 个 1,线性复杂度。
使用
q.push_front(数据) 在头部插入一个元素,常数复杂度。
q.push_back(数据) 在尾部插入一个元素,常数复杂度。
q.insert() 在某个位置插入元素,需要结合迭代器使用,线性复杂度。
q.pop_front() 删除头部元素,常数复杂度。
q.pop_back() 删除尾部元素,常数复杂度。
q.erase() 在某个位置删除元素,需要结合迭代器使用,线性复杂度。
q.size() 或 q.length() 获取长度
q[i] 获取下标为 i 的元素
q.front()获取首位元素,也可以使用下标 q[0]
q.back() 获取末尾元素,也可以使用下标 q[q.size()-1]
q.clear() 清空容器
q.begin() 返回一个迭代器,指向容器的第一个元素
q.end() 返回一个迭代器,指向容器的最后一个元素的后一位
可以发现大部分操作其实和 vector 类似,只是其底层实现原理是多个不连续的缓冲区,以此做到了 常数级的 头尾增删 和 常数级的随机访问。
set
set 是按照特定顺序存储唯一元素的容器,即自带排序和去重。其内部一般用 红黑树 来实现,因此它非常适合处理需要同时兼顾查找、插入和删除的情况。需要注意的是,元素放入 set 后不支持修改,但可以删除。
和数学中的集合相似,set 中不会出现值相同的元素,如果需要有相同元素,则可以使用 multiset ,multiset 除了此特性之外,其他地方与 set 没啥区别,所以不再单独介绍。
定义
格式:set<类型> 变量名;
例如:set<int> s; 定义了一个 int 类型的空集合。
插入与删除操作
s.insert(x)当容器中没有等价元素的时候,将元素x插入到set中。s.erase(x)删除值为x的 所有 元素,返回删除元素的个数。s.erase(pos)删除迭代器为pos的元素,要求迭代器必须合法。s.erase(first,last)删除迭代器在范围内的所有元素。 s.clear()清空set。
查找操作
s.count(x)返回set内键为 x 的元素数量。s.find(x)在set内存在键为 x 的元素时会返回该元素的迭代器,否则返回end()。s.lower_bound(x)返回指向首个不小于给定键的元素的迭代器。如果不存在这样的元素,返回end()。s.upper_bound(x)返回指向首个大于给定键的元素的迭代器。如果不存在这样的元素,返回end()。s.empty()返回容器是否为空。s.size()返回容器内元素个数。
map
map 是有序键值对容器,它的元素的键是唯一的。搜索、移除和插入操作拥有对数复杂度。map 通常实现为 红黑树。
设想如下场景:现在需要存储一些键值对,例如存储学生姓名对应的分数:Tom 0,Bob 100,Alan 100。但是由于数组下标只能为非负整数,所以无法用姓名作为下标来存储,这个时候最简单的办法就是使用 STL 中的 map。(有同学会说可以用结构体数组,但如果我接下来想快速找到 Tom 的分数呢?结构体数组得循环遍历,而 map 只需要 log(n) 。)
定义
map 重载了 operator[],可以用任意定义了 operator < 的类型作为下标(在 map 中叫做 key,也就是索引):
map<Key, T> yourMap;
其中,Key 是键的类型,T 是值的类型,下面是使用 map 的实例:
map<string, int> mp;
map 中不会存在键相同的元素,multimap 中允许多个元素拥有同一键。multimap 的使用方法与 map 的使用方法基本相同。
multimap 无法使用键直接访问对应值。
插入与删除操作
- 可以直接通过下标访问来进行查询或插入操作。例如
mp["Alan"]=100,这种方式比较常见。 - 也可以通过向
map中插入一个类型为pair<Key, T>的值可以达到插入元素的目的,例如mp.insert(pair<string,int>("Alan",100));; erase(key)函数会删除键为key的 所有 元素。返回值为删除元素的数量。erase(pos): 删除迭代器为 pos 的元素,要求迭代器必须合法。erase(first,last): 删除迭代器在范围内的所有元素。 clear()函数会清空整个容器。
查询操作
- 直接通过下标访问,进行查询,例如
cout << mp["Alan"]; count(x): 返回容器内键为 x 的元素数量。复杂度为(关于容器大小对数复杂度,加上匹配个数)。 find(x): 若容器内存在键为 x 的元素,会返回该元素的迭代器;否则返回end()。lower_bound(x): 返回指向首个不小于给定键的元素的迭代器。upper_bound(x): 返回指向首个大于给定键的元素的迭代器。若容器内所有元素均小于或等于给定键,返回end()。empty(): 返回容器是否为空。size(): 返回容器内元素个数。
在利用下标访问 map 中的某个元素时,如果 map 中不存在相应键的元素,会自动在 map 中插入一个新元素,并将其值设置为默认值(对于整数,值为零;对于有默认构造函数的类型,会调用默认构造函数进行初始化)。
所以当下标访问操作过于频繁时,容器中会出现大量无意义元素,影响 map 的效率。因此一般情况下推荐使用 find() 函数来寻找特定键的元素。
无序关联式容器
前文介绍了四种基于哈希实现的容器:unordered_set,unorderer_multiset,unordered_map,unordered_multimap 。
它们的使用上与其对应的关联式容器基本共通,区别在于关联式容器一般用红黑树实现,内部元素会进行排序;而这几种无序关联式容器则采用哈希方式存储元素,内部元素不会进行排序,在访问其中元素时,顺序不会得到保证。
而使用哈希存储的特点,是在平均情况下大部分操作都可以用常数时间复杂度完成,在特定场景下不需要元素进行排序时,使用无序关联式容器可以让程序速度更快。
虽然查询之类的操作是常数级别,但是当数据中出现大量哈希冲突时,会使得操作变为线性级,所以避免滥用。
当然,如果是需要记录一些复杂状态,并且不要求排序时,使用无序关联式容器可以让我们的代码好写很多。
pair
pair 严格意义来说并不属于容器,可以把它当作简单版本的结构体,一个 pair 对象可以包含两个元素,在语法和对STL库的支持上,pair 比 结构体更加简便一些,在实现 一些算法时可以用 pair 来快速建立键值关系。
定义
格式:pair<类型, 类型> 变量名;
pair<int, double> p1; //定义p1为pair类型,包含一个整数和一个浮点数
pair<int, int> p2 = {1, 3}; // 直接赋值
pair<int, double> p[10]; //定义pair类型的数组p[]
pair<string, string> book("lcx","three body"); //定义book是pair类型且初始化
vector<pair<int,int>> p3; // 定义一个元素类型是 pair 的 vector容器
使用
访问第一个元素:名字.first
访问第二个元素:名字.second
//pair示例程序1
#include <iostream>
#include <utility>
using namespace std;
int main() {
pair<int, double> p1;
p1.first = 10;
p1.second = 12.5;
cout << p1.first << ' ' << p1.second << endl;
return 0;
}
pair 类型的变量可以直接用关系运算符来进行比较,先比较第一个元素,如果第一个元素相等, 再比较第二个。需要注意的是,两个 pair 必须关联的元素类型是相同的才可以比较,例如 pair<int,int> 只能和 pair<int,int> 类型进行比较。
#include <bits/stdc++.h>
using namespace std;
int main() {
pair<int, int> a = {3, 1};
pair<int, int> b = {2, 2};
pair<int, int> c = {3, 2};
cout << (a > b) << '\n'; // 结果为 1
cout << (a > c) << '\n'; // 结果为 0
return 0;
}
pair 相较于 结构体,在使用 sort 时,pair 的数组可以直接默认从小到大排序,而结构体则仍需自定义比较规则或者重构运算符,略显麻烦。